GazeAnywhere: Gaze Target Estimation Anywhere with Concepts
What if you could ask an AI "where is the boy in the red shirt looking?" and get an instant answer from any image? GazeAnywhere is the first foundation model that understands gaze through natural language.
Estimating where people are looking in real-world images is notoriously tough. Current methods rely on brittle, multi-stage pipelines that require rigid inputs like head bounding boxes and human pose. Detection errors cascade through the pipeline, and there’s no way to use natural language to specify who you want to analyze.
💡 Key Idea: Promptable Gaze Target Estimation
We define a new task — Promptable Gaze Target Estimation (PGE) — that replaces fragile pipelines with a single, flexible model:
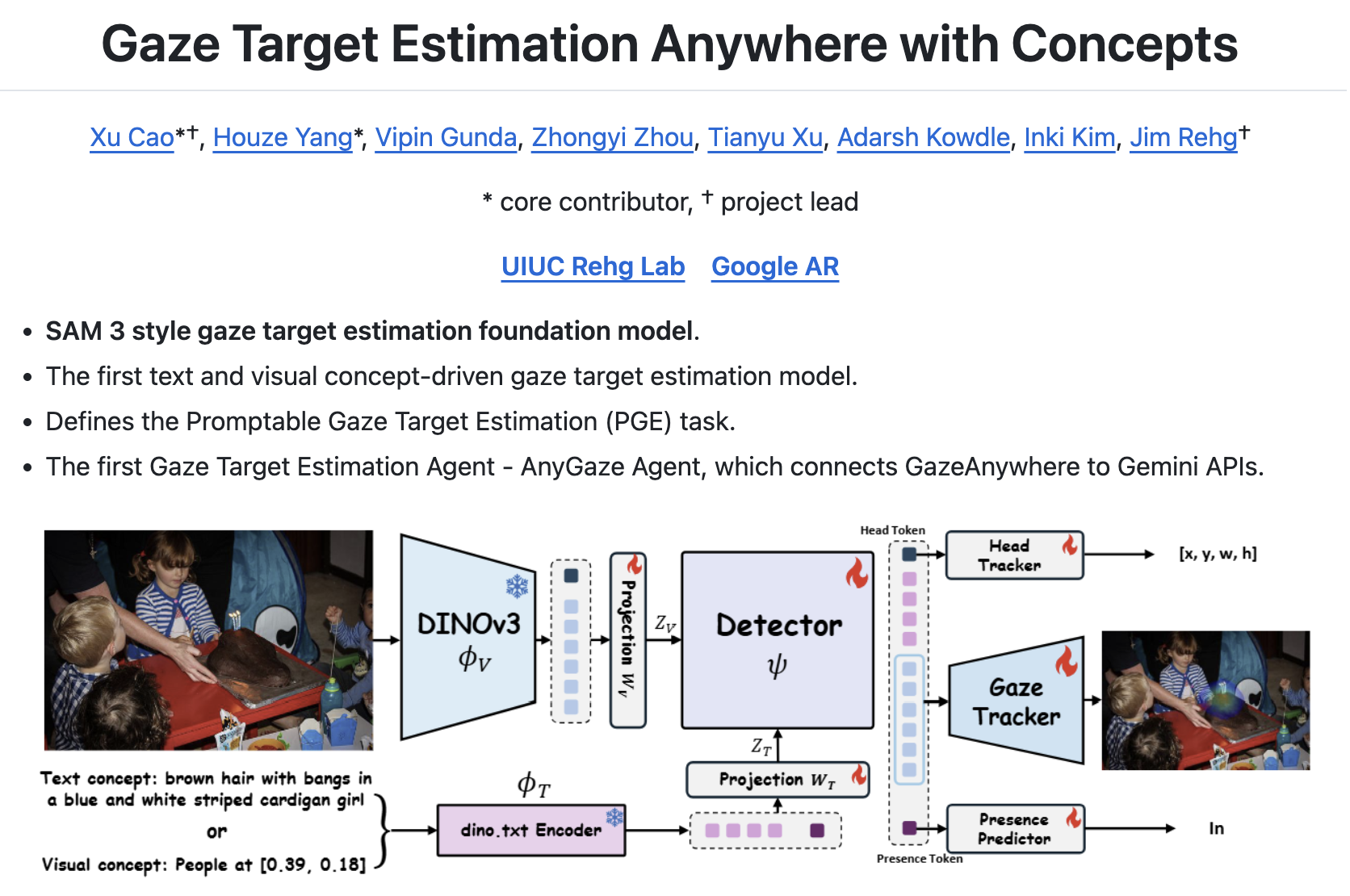
**Flexible Prompting** Use natural language ("the boy in the red shirt") or visual prompts (a specific coordinate) to identify who you want to analyze. **End-to-End Integration** PGE merges subject localization with gaze estimation in a single pass — no cascading errors. **Foundation Model Architecture** GazeAnywhere uses a multi-layer transformer to simultaneously solve subject localization, in/out-of-frame presence, and gaze target heatmap estimation.
⚡ Why GazeAnywhere?
🔬 SAM 3-style gaze target estimation foundation model
💬 The first text and visual concept-driven gaze estimation model
📋 Defines the Promptable Gaze Target Estimation (PGE) task
🤖 Includes AnyGaze Agent — connecting GazeAnywhere to Gemini APIs
Estimating human gaze targets from images in-the-wild is an important and formidable task. Existing approaches primarily employ brittle, multi-stage pipelines that require explicit inputs, like head bounding boxes and human pose. We introduce the Promptable Gaze Target Estimation (PGE) task, a new end-to-end, concept-driven paradigm for gaze analysis that conditions gaze prediction on flexible user text or visual prompts. We propose GazeAnywhere, the first foundation model designed for PGE, which uses a multi-layer transformer-based detector to fuse features from frozen encoders and simultaneously solves subject localization, in/out-of-frame presence, and gaze target heatmap estimation.
@inproceedings{cao2026gazeanywhere,author={Cao, Xu and Yang, Houze and Gunda, Vipin and Zhou, Zhongyi and Xu, Tianyu and Kowdle, Adarsh and Kim, Inki and Rehg., James M.},title={{Gaze Target Estimation Anywhere with Concepts}},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026)},year={2026},keywords={gaze estimation, foundation model, promptable vision, computer vision, SAM, transformer},}

 In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026)
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2026)