MoXaRt: Audio-Visual Object-Guided Sound Interaction for XR
MoXaRt is a real-time XR system that uses audio-visual cues to separate entangled sound sources and enable fine-grained sound interaction. Accepted to CHI 2026, Barcelona, Spain.
Overview
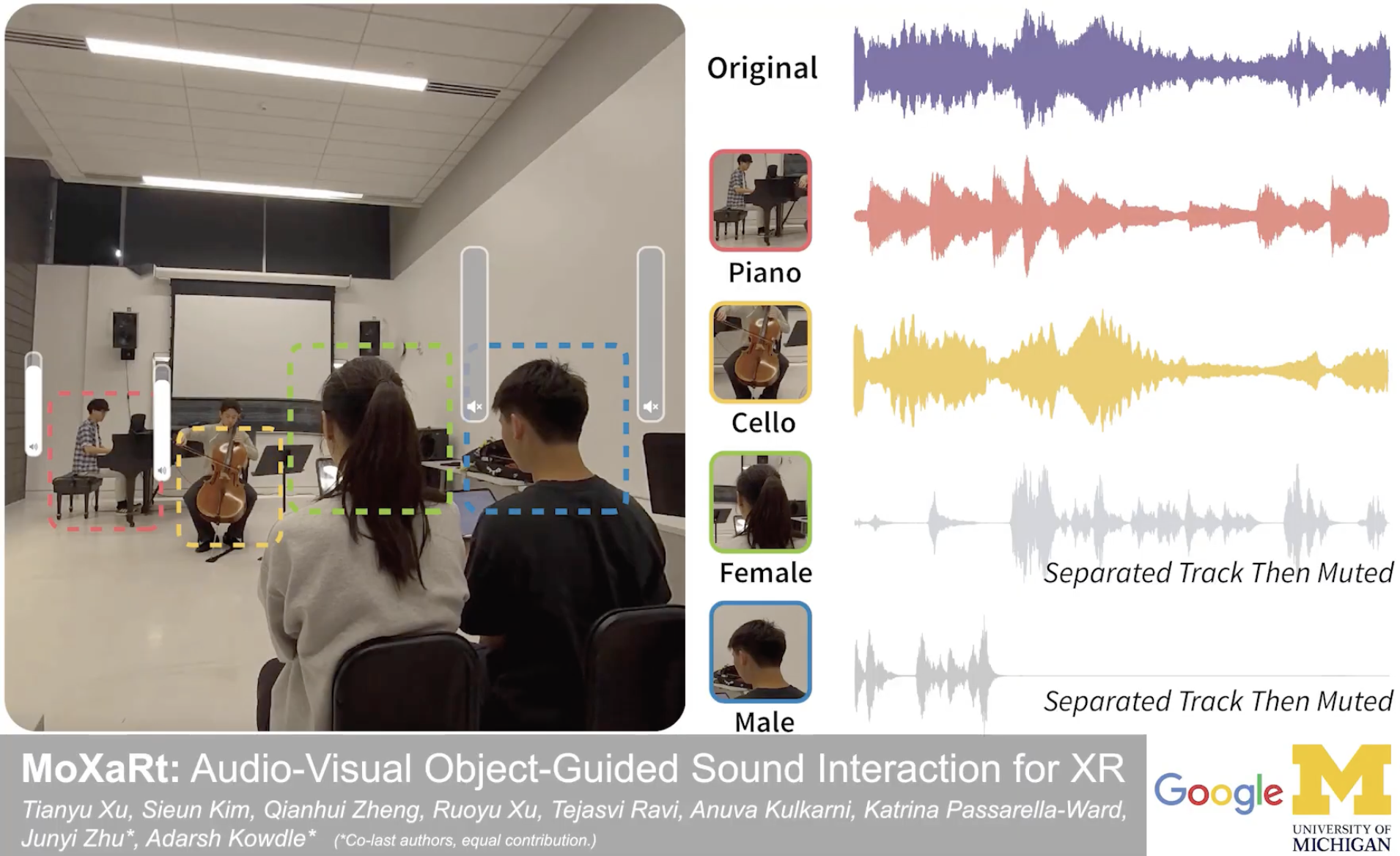
MoXaRt’s core is a cascaded architecture that performs:
Coarse audio-only separation — initial separation of mixed audio sources
Visual detection of sources — identifying sound-producing objects (e.g., faces, instruments) in the scene
Visually-guided refinement — using the visual anchors to isolate individual sources with high precision
The system separates complex mixes of up to 5 concurrent sources (e.g., 2 voices + 3 instruments) with approximately ~2 second processing latency, making it suitable for real-time XR interaction.
Results
We validated MoXaRt through a technical evaluation on a new dataset of 30 one-minute recordings featuring concurrent speech and music, and a 22-participant user study.
Metric
Result
Speech intelligibility
36.2% increase in listening comprehension (p < 0.01)
In Extended Reality (XR), complex acoustic environments often overwhelm users, compromising both scene awareness and social engagement due to entangled sound sources. We introduce MoXaRt, a real-time XR system that uses audio-visual cues to separate these sources and enable fine-grained sound interaction. MoXaRt’s core is a cascaded architecture that performs coarse, audio-only separation in parallel with visual detection of sources (e.g., faces, instruments). These visual anchors then guide refinement networks to isolate individual sources, separating complex mixes of up to 5 concurrent sources (e.g., 2 voices + 3 instruments) with 2 second processing latency. We validate MoXaRt through a technical evaluation on a new dataset of 30 one-minute recordings featuring concurrent speech and music, and a 22-participant user study. Empirical results indicate that our system significantly enhances speech intelligibility, yielding a 36.2% (p < 0.01) increase in listening comprehension within adversarial acoustic environments while substantially reducing cognitive load (p < 0.001), thereby paving the way for more perceptive and socially adept XR experiences.
@inproceedings{xu2026moxart,author={Xu, Tianyu and Kim, Sieun and Zheng, Qianhui and Xu, Ruoyu and Ravi, Tejasvi and Kulkarni, Anuva and Passarella-Ward, Katrina and Zhu, Junyi and Kowdle., Adarsh},title={{MoXaRt: Audio-Visual Object-Guided Sound Interaction for XR}},booktitle={Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI '26)},year={2026},address={Barcelona, Spain},publisher={Association for Computing Machinery},keywords={extended reality, audio-visual interaction, multimodal machine learning, spatial audio, sound synthesis, object-guided interaction},doi={10.1145/3772318.3791929},}