MoXaRt: Audio-Visual Object-Guided Sound Interaction for XR

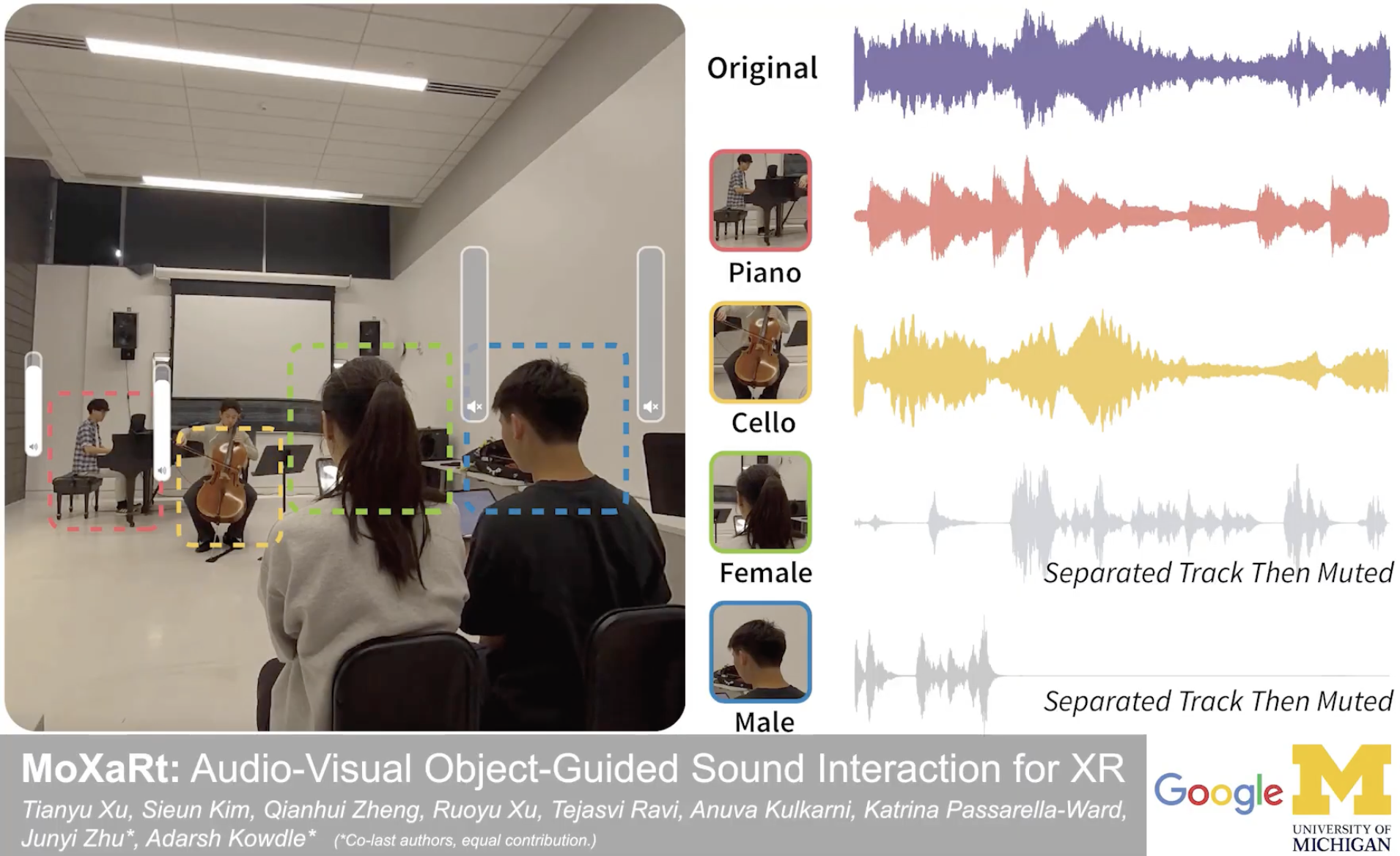
Imagine sitting in a noisy café where a guitarist, a cellist, and two people are all talking at once. What if your XR headset could let you tap on the guitarist to hear only their melody — or mute a conversation you're not part of? That's MoXaRt.
📄 Paper: arXiv:2603.10465 · Accepted to CHI 2026
🎤 Talk: Fri, Apr 17 at 9:00 AM
📍 Barcelona International Convention Centre, P1 — Room 128
🎯 The Problem
In real-world XR environments, sound sources are entangled — voices overlap with music, instruments bleed into each other. Existing spatial audio techniques can filter by direction, but they can’t separate two sources coming from the same location.
MoXaRt solves this by combining what you see with what you hear — using visual detection of sound-producing objects (faces, instruments) to guide precise audio separation.
🏗️ How It Works
MoXaRt uses a cascaded architecture with three stages:
🎬 Demos
See MoXaRt in action — real-time source separation controlled through visual object selection.
Instrument Separation
A live performance with multiple instruments playing simultaneously. MoXaRt identifies each instrument visually and separates their audio streams in real time.
Speech vs. Music Separation
A scenario with overlapping speech and background music — MoXaRt cleanly separates the two, letting you focus on either the conversation or the performance.
Multi-Speaker Separation
Multiple people speaking at once. By visually selecting a specific person, MoXaRt isolates their voice from the crowd.
📊 Results
We validated MoXaRt through a technical evaluation on a new dataset of 30 one-minute recordings featuring concurrent speech and music, and a 22-participant user study.
| Metric | Result |
|---|---|
| Speech intelligibility | 36.2% increase in listening comprehension (p < 0.01) |
| Cognitive load | Significantly reduced (p < 0.001) |
| Concurrent sources | Up to 5 (e.g., 2 voices + 3 instruments) |
| Processing latency | ~2 seconds |